ポアソン分布への適合度の検定 Last modified: Jan 09, 2015
目的
ポアソン分布への適合度の検定を行う
使用法
poissondist(d, x)
summary.poissondist(obj, digits=5)
plot.poissondist(obj, ...)
引数
d 度数ベクトル
x 階級値ベクトル
obj poissondist 関数が返すオブジェクト
digits 表示桁数
... barplot に渡す引数
ソース
インストールは,以下の 1 行をコピーし,R コンソールにペーストする
source("http://aoki2.si.gunma-u.ac.jp/R/src/poissondist.R", encoding="euc-jp")
# ポアソン分布への適合度の検定
poissondist <- function(d, # 度数ベクトル
x=NULL) # 階級値ベクトル
{
if (is.null(x)) {
stop("関数の仕様が変更されました。度数ベクトルと同じ長さの階級値ベクトルも指定してください。")
}
data.name <- paste(deparse(substitute(d)), deparse(substitute(x)), sep=", ")
method <- "ポアソン分布への適合度の検定"
k <- length(d) # 階級数
if (length(x) != k) {
stop("度数ベクトル階級値ベクトルの長さは同じでなければなりません。")
}
o <- numeric(diff(range(x))+1)
o[x-min(x)+1] <- d
x <- min(x):max(x)
k <- length(o) # 階級数
n <- sum(o) # データ数
lambda <- sum(o*x)/n # 平均値(=λ)
p <- dpois(x, lambda) # 確率
p[1] <- ppois(min(x), lambda) # 最初と最後の階級値の確率は階級値以下・以上の確率を併合する
p[k] <- ppois(max(x)-1, lambda, lower.tail=FALSE)
e <- n*p # 期待値
table <- data.frame(x, o, p, e) # 結果をデータフレームにまとめる
rownames(table) <- paste("c-", x, sep="")
while (e[1] < 1) { # 1 未満のカテゴリーの併合
o[2] <- o[2]+o[1]
e[2] <- e[2]+e[1]
o <- o[-1]
e <- e[-1]
k <- k-1
}
while (e[k] < 1) { # 1 未満のカテゴリーの併合
o[k-1] <- o[k-1]+o[k]
e[k-1] <- e[k-1]+e[k]
o <- o[-k]
e <- e[-k]
k <- k-1
}
chisq <- sum((o-e)^2/e) # カイ二乗統計量
df <- k-2 # 自由度
p <- pchisq(chisq, df, lower.tail=FALSE) # P 値
names(chisq) <- "X-squared"
names(df) <- "df"
return(structure(list(statistic=chisq, parameter=df, p.value=p,
estimate=c(n=n, lambda=lambda), method=method,
data.name=data.name, table=table), class=c("htest", "poissondist")))
}
# summary メソッド
summary.poissondist <- function(obj, # poissondist が返すオブジェクト
digits=5)
{
table <- obj$table
colnames(table) <- c("階級", "度数", "確率", "期待値")
cat("\n適合度\n\n")
print(table, digits=digits, row.names=FALSE)
}
# plot メソッド
plot.poissondist <- function(obj, # poissondist が返すオブジェクト
...) # barplot へ渡す引数
{
table <- obj$table
nr <- nrow(table)
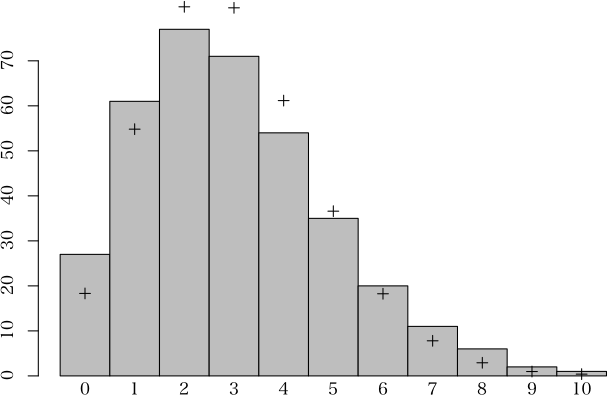
posx <- barplot(table$o, space=0, ...) # 観察度数を barplot で描く
old <- par(xpd=TRUE)
points(posx, table$e, pch=3) # 理論度数を,記号 + で示す
text(posx, -strheight("H"), table$x)
par(old)
}
使用例
> d <- c(27, 61, 77, 71, 54, 35, 20, 11, 6, 2, 1)
> x <- 0:10
> (a <- poissondist(d, x))
ポアソン分布への適合度の検定
data: d, x
X-squared = 14.1437, df = 8, p-value = 0.0781
sample estimates:
n lambda
365.000000 2.991781
> summary(a)
適合度
階級 度数 確率 期待値
0 27 0.0501980 18.32226
1 61 0.1501813 54.81618
2 77 0.2246548 81.99899
3 71 0.2240393 81.77434
4 54 0.1675691 61.16272
5 35 0.1002660 36.59709
6 20 0.0499957 18.24841
7 11 0.0213680 7.79932
8 6 0.0079910 2.91673
9 2 0.0026564 0.96958
10 1 0.0010805 0.39437
> plot(a)
 > f <- c(1, 2, 8, 8, 10, 15, 12, 15, 12, 6, 3, 1, 2, 0, 1)
> x <- 1:15
> (a <- poissondist(f, x))
ポアソン分布への適合度の検定
data: f, x
X-squared = 5.2851, df = 11, p-value = 0.9166
sample estimates:
n lambda
96.000000 6.864583
> f <- c(1, 2, 8, 8, 10, 15, 12, 15, 12, 6, 3, 1, 2, 0, 1)
> x <- 1:15
> (a <- poissondist(f, x))
ポアソン分布への適合度の検定
data: f, x
X-squared = 5.2851, df = 11, p-value = 0.9166
sample estimates:
n lambda
96.000000 6.864583
 解説ページ
解説ページ
直前のページへ戻る E-mail to Shigenobu AOKI
