No.20327 Re: semについて 【コロン】 2013/10/17(Thu) 18:36
AMOSで作成したパス図を掲載いたします。
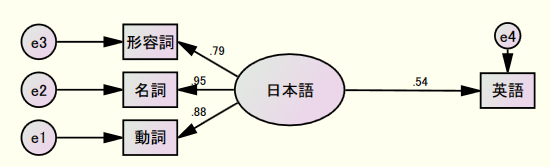
model<-specifyModel()用いた相関行列は以下の通りです。念のために共分散行列も次に示します。
英語 <- 日本語, b1, NA #パス係数
形容詞 <- 日本語, b2, NA
動詞 <- 日本語, b3, NA
名詞 <- 日本語, NA, 1 #パスを固定
形容詞 <-> 形容詞, e1, NA
動詞 <-> 動詞, e2, NA
名詞 <-> 名詞, e3, NA
日本語 <-> 日本語, e4, NA
英語 <-> 英語, e5, NA
形容詞 名詞 動詞 英語これらを用いて分析をし,パス図を描きます。また適合度などもsummaryを用いて計算します。
形容詞 1.0000000 0.7500981 0.7067367 0.2767175
名詞 0.7500981 1.0000000 0.8295078 0.5271663
動詞 0.7067367 0.8295078 1.0000000 0.5108690
英語 0.2767175 0.5271663 0.5108690 1.0000000
形容詞 名詞 動詞 英語
形容詞 3.284848 2.482828 3.005724 10.17138
名詞 2.482828 3.335354 3.554882 19.52559
動詞 3.005724 3.554882 5.506397 24.31246
英語 10.171380 19.525589 24.312458 411.31178
ans<-sem(model, a, 55) #aは相関または共分散行列のオブジェクト名質問は次の通りです。
pathDiagram(ans, "new", ignore.double=FALSE, stdCoef=T,edge.labels="values",
digits=3, min.rank=c("形容詞", "名詞","動詞"), node.font=c("Osaka", 10))
> summary(ans)(2)標準解で求めた場合,パス図の潜在変数「日本語」から観測変数「名詞」へのパス係数の表示が1のままです。なぜでしょうか。
Model Chisquare = 5.67071 Df = 2 Pr(>Chisq) = 0.0586977
AIC = 21.67071
BIC = -2.343957
No.20318 Re: semについて 【コロン】 2013/10/17(Thu) 08:53
前の書き込みを読まずに投稿しました。申し訳ありません。
類似の質問があります(私ではありませが)。
私の場合は,Mac OSは最新のものです。
ご指導お願いいたします。
No.20319 Re: semについて 【青木繁伸】 2013/10/17(Thu) 10:02
summary で呼ばれるのは summary.msemObjectiveML になります。
? summary.msemObjectiveML を読めば分かりますが,以下のようにすればよいでしょう。
fit.indices で,必要なものだけを指定することができます。
summary(ans, fit.indices=c("GFI", "AGFI", "RMSEA", "NFI", "NNFI", "CFI", "RNI", "IFI", "SRMR"))
No.20321 Re: semについて 【コロン】 2013/10/17(Thu) 10:10
青木先生
早速のお返事ありがとうございます。summaryで複数の適合度を計算することができました。
また標準解で1が表示されるのもご存じでしたらご教授いただけましたら幸いに存じます。
No.20322 Re: semについて 【青木繁伸】 2013/10/17(Thu) 14:55
> 標準解で1が表示されるのもご存じでしたらご教授いただけましたら幸いに存じます。
どれか一つを1に固定しないと解が得られないのではなかったでしょうか(それがお約束?)
No.20323 Re: semについて 【コロン】 2013/10/17(Thu) 16:49
青木先生
ありがとうございます。あい,私は過去Amos userでしたので,1を固定することは承知しております。ただ最終のモデル図でそれが1として表示されるのがわかりません。青木先生のご説明のところ (下記URL)でも,1に固定されたものが,結果としては正しい答えとして表示されております。
http://aoki2.si.gunma-u.ac.jp/lecture/sem/pathDiagram.html
いろいろと見ながら,何度もモデルの式を確認しているのですが,解決には至っていない次第です。
よろしくお願いいたします。
No.20324 Re: semについて 【青木繁伸】 2013/10/17(Thu) 16:54
> 最終のモデル図でそれが1として表示されるのがわかりません
初期値を1にする必要があるというのではなく,モデル全体として1(定数)にしないと成り立たないということでは?なので,結果でも1のまま。
No.20325 Re: semについて 【コロン】 2013/10/17(Thu) 18:00
青木先生
私の理解がおかしいのかも知れませんが,つまりモデルがおかしいということなのでしょうか。
最 近は全く使わなくなったAMOSで同じデータを試してみたところ,AMOSではきちんと標準解が得られました。先生の例(先ほどの書き込みのURL)やそ の他のサイトも見てみたのですが,きちんと表現されていますので,私のRのモデルの書き方が不味いのかと考え,いろいろと試してはいるのですが....。
私の誤解であれば申し訳ございません。
No.20326 Re: semについて 【青木繁伸】 2013/10/17(Thu) 18:36
よく見ていませんでした。標準解のときも1が表示されるのは何故かということだったんですね。
それは,,,あなたが,引数の指定を間違えたからです。
stdCoef=T ではなく,standardize=T でしょう(TRUE を T と書くのもお勧めではないが)
No.20327 Re: semについて 【コロン】 2013/10/17(Thu) 18:36
AMOSで作成したパス図を掲載いたします。
No.20328 Re: semについて 【コロン】 2013/10/17(Thu) 18:51
青木先生
いろいろとありがとうございました。
standardize=TRUE
でうまくいきました。私が参考にしたウェブ,本には
stdCoef=T
が書かれてあったために,そのまま使いました。また適合度につきましてもsummary(オブジェクト名)ですべて出力されるような書き方だったので,なぜうまくいかないのか,疑問で仕方がありませんでした。
青木先生のサイトには standardize=TRUEとございました。もっと早くそしてきちんと見比べておくべきでした。反省です。
それからどうでも良い質問になってしまうかも知れませんが,なぜTRUEをTと書くのがお勧めできないのかの理由を聞かせて頂けると幸いに存じます。
No.20329 Re: semについて 【青木繁伸】 2013/10/17(Thu) 19:00
sem はだいぶ前に,大幅に変わりました。
T と F は初期状態では TRUE と FALSE という値を保持していますが,代入可能なのです。
で,どこかでうっかり(意図して)代入してしまうと,期待したのと違う動作になってしまいます。> T
[1] TRUE
> T <- 123
> T
[1] 123
> T <- FALSE
> T
[1] FALSE
> if (T) print("TRUE") # なにも表示されない
> F <- 1.234
> F
[1] 1.234
No.20330 Re: semについて 【コロン】 2013/10/17(Thu) 19:13
青木先生
semは大幅に変更になったのですね。私が閲覧したサイトは古い情報だということで理解いたしました。やはり先生のページをフォローするのが一番いいということを改めて感じました。
またTRUEとTの件についても,ありがとうございました。勉強になりました。
● 「統計学関連なんでもあり」の過去ログ--- 046 の目次へジャンプ
● 「統計学関連なんでもあり」の目次へジャンプ
● 直前のページへ戻る