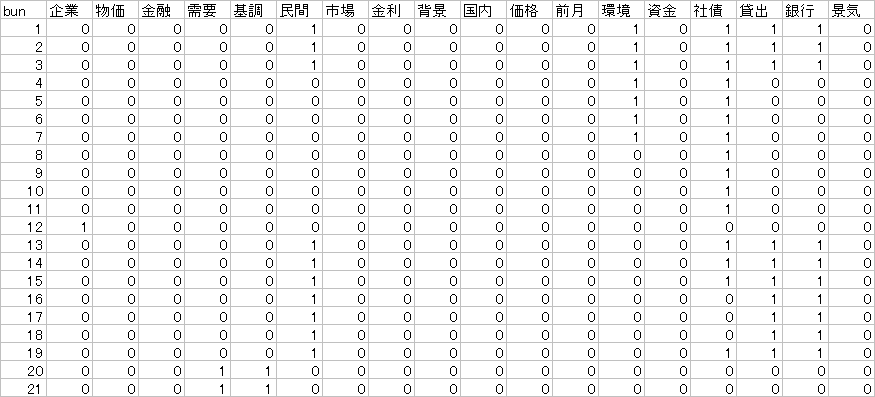
No.21626 Re: 【R】行列のデータハンドリング 【青木繁伸】 2015/04/25(Sat) 20:57
dat にデータを読み込んだ後
以下の一文を> doc <- apply(dat, 1, function(x) {ban1 <- which(x > 0); vec1 <- x[ban1]; rbind(ban1, vec1)})
実行結果
> head(doc)
$`1`
金利
ban1 9
vec1 2
$`2`
需要 国内
ban1 5 11
vec1 1 2
$`3`
金利 価格
ban1 9 12
vec1 1 1
> doc[[1]]
金利
ban1 9
vec1 2
No.21627 【御礼】 Re: 【R】行列のデータハンドリング 【赤羽】 2015/04/25(Sat) 21:31
青木先生,
赤羽と申します,ご教示をいただき誠にありがとうございます。
まさか,本当にループを回避できるとは,驚きました。
『はじめてのR: ごく初歩の操作から統計解析の導入まで』村井潤一郎(北大路書房/2013年)
の中に,
apply族については,青木先生の著書がとても詳しい,
と書かれていた記憶がございますが,本当にその通りでした。
勇気を振り絞って,投稿させていただき,大変に良い勉強をさせていただきました。
心から,心より,御礼を申し上げます,
● 「統計学関連なんでもあり」の過去ログ--- 047 の目次へジャンプ
● 「統計学関連なんでもあり」の目次へジャンプ
● 直前のページへ戻る